
Від REST API до MCP: як навчити ШІ користуватися бекендом
- Катерина Шевченко

- 16 черв.
- Читати 8 хв

Ще півтора року тому компанії побоювалися використовувати штучний інтелект через ризики витоку конфіденційних даних, але сьогодні бізнес активно вимагає від розробників складних інтеграцій, зокрема з використанням Model Context Protocol (MCP).
Олександр Зіневич, Director of Competency в Avenga, поділився практичним досвідом інтеграції корпоративного бекенду зі штучним інтелектом. Під час виступу на конференції AI JavaScript fwdays'26 він розповів, як за допомогою Model Context Protocol (MCP) навчити великі мовні моделі користуватися реальними даними компанії на прикладі застосунку для нафтогазової індустрії, а також про виклики переходу від класичного REST API до створення власного MCP-сервера. Публікуємо найважливіше з виступу.

Як все починалося
Протягом семи років команда розробляла монолітний застосунок, який функціонує як дуже просунутий науково-інженерний калькулятор. Цей інструмент допомагає інженерам та науковцям робити надскладні розрахунки для правильного буріння нафтових та газових свердловин, опрацьовуючи величезні масиви даних.
Технологічний зсув на проєкті розпочався з того, що CTO клієнтської компанії ініціював внутрішню AI-трансформацію. Згодом він прийшов до команди з конкретною бізнес-потребою: інтегрувати існуючий бекенд із його даними безпосередньо в інтерфейс Claude. Головна мета полягала в тому, щоб надати працівникам можливість робити розрахунки за допомогою реальних, точних даних компанії, тим самим повністю виключивши ризик галюцинацій мовної моделі. Саме цей запит став відправною точкою у пошуку рішень, як навчити ШІ користуватися їхнім бекендом, що в результаті призвело до розробки власного MCP-сервера.
Що таке Model Context Protocol (MCP)
Згадайте часи, коли ChatGPT тільки почав набирати обертів: поява фічі, яка дозволяла моделі самостійно викликати певну JavaScript-функцію, здавалася справжньою фантастикою. Проте це була ексклюзивна можливість лише однієї платформи. Щоб реалізувати подібну інтеграцію для будь-якої іншої LLM, розробникам доводилося кожного разу писати з нуля абсолютно нову логіку.
Саме для вирішення цієї проблеми фрагментації компанія Anthropic розробила Model Context Protocol (MCP). Це відкритий стандарт, головна мета якого — надати великим мовним моделям (LLM) безпечний та стандартизований доступ до зовнішнього світу, корпоративних даних та сторонніх сервісів.
Цей протокол можна назвати USB Type-C для штучного інтелекту. MCP інкапсулює під капотом усю складну логіку взаємодії з вашим бекендом чи сервісом, а назовні видає стандартизовані методи. Завдяки цьому будь-який клієнт, що підтримує цей стандарт, може легко підключитися до вашої системи і почати з нею працювати без написання унікальних кастомних інтеграцій під кожну окрему мовну модель.

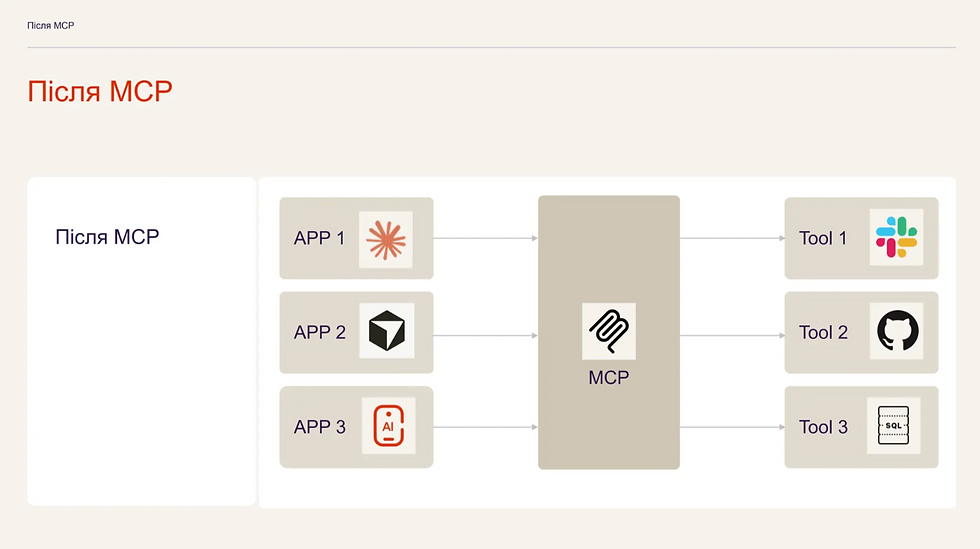
Як працює MCP
Щоби зрозуміти, як саме ШІ спілкується з бекендом, важливо розібратися у ключових компонентах архітектури протоколу. Все починається з MCP Host — це середовище, де користувач взаємодіє з моделлю, наприклад, Claude Desktop або вебовий ChatGPT. Усередині кожного такого хоста працює MCP Client, який непомітно для користувача відповідає за встановлення сесії з вашим MCP Server. Спілкування між ними стартує з етапу, що називається capabilities negotiation — клієнт і сервер обмінюються інформацією про те, які можливості кожен з них підтримує.
За замовчуванням ваш MCP-сервер може надавати клієнту три основні сутності:
Tools — конкретні виконувані функції, які вміє робити ваш сервер.
Prompts — готові шаблони використання даного сервера для швидкого та правильного старту роботи.
Resources — великі об'єми контекстних даних, які сервер може надати моделі за потреби, щоб не підвантажувати їх усі одразу і не переповнювати контекст.
Окрім цих базових речей, протокол передбачає розширені можливості, про підтримку яких клієнт повідомляє серверу під час встановлення з'єднання:
Elicitation: якщо для виконання певного тулу мовному помічнику не вистачає вхідних параметрів, сервер може ініціювати запит до кінцевого користувача (наприклад, через нативне модальне вікно) з проханням уточнити дані.
Roots: дозвіл від клієнта на роботу з певною виділеною частиною локальної файлової системи.
Sampling: можливість MCP-сервера попросити клієнта скористатися потужностями LLM для виконання якогось проміжного кроку чи обробки інформації.
Проте тут криється важливий нюанс для розробників: якщо базові тули підтримують майже всі платформи, то розширені можливості Roots чи Sampling з популярних мейнстрімних інструментів повноцінно підтримує хіба що GitHub Copilot. Тому при проектуванні архітектури MCP-сервера потрібно чітко розуміти, які саме клієнти будуть ним користуватися, щоб не витрачати час на імплементацію фіч, які кінцевий інтерфейс просто не зможе відобразити.

Перехід від REST до MCP та технологічний стек
Щоб інтегрувати існуючий бекенд у MCP, команді довелося суттєво змінити підхід до архітектури. Вихідні дані проєкту виглядали так: монолітний застосунок (якому вже близько семи років) із фронтендом на React, бекендом на Nest.js та базою даних PostgreSQL. Хоча загалом архітектура бекенду монолітна, деякі специфічні та критичні вузли все ж були винесені окремо. Наприклад, логіка прав доступу реалізована як мікросервіс — для цього команда побудувала власний permission framework на основі рішення Castle.

Оскільки бекенд написаний на Node.js, для інтеграції використали офіційне TypeScript SDK для MCP, яке підтримує всі нові фічі протоколу «з коробки» та оновлюється швидко. Для Python, C# (.NET) чи Go підтримка нових функцій може з'являтися із затримкою або бути лише частковою.
Перенесення логіки з REST API на MCP — це не просто переписування коду, це кардинальна зміна парадигми взаємодії, яка включає кілька ключових відмінностей:

Stateful замість Stateless: нові правила управління сесіями
Однією з найвідчутніших змін при переході з REST API на Model Context Protocol є кардинальна зміна підходу до збереження стану. Класичний REST-підхід працює без збереження стану (stateless), тоді як MCP за своєю природою є stateful-протоколом. Для повноцінної роботи він вимагає створення сесій, і для цього є дві фундаментальні причини:
Двостороння комунікація. На відміну від звичного циклу «запит-відповідь» у REST, де ініціатором завжди виступає клієнт, MCP підтримує двосторонній зв'язок. Сервер може самостійно ініціювати надсилання нотифікацій клієнту, наприклад, щоб повідомити про зміну списку тулів.
Збереження історії та контексту. За задумом розробників протоколу, MCP-сервер повинен тримати історію взаємодії з користувачем. Це дозволяє серверу продовжувати роботу, враховуючи попередній контекст, а також коректно відновлювати сесію у разі виникнення будь-яких технічних проблем.
Хоча створення сесій є базовою вимогою протоколу, на практиці для запуску першої MVP-версії це не завжди критично необхідно. Команда знайшла спосіб обійти це правило та налаштувати роботу так, щоб кожного разу створювалася нова сесія. Для цього достатньо примусово передавати параметр state id undefined. Це змушує клієнта щоразу перестворювати з'єднання при кожному новому виклику, що фактично робить процес stateless. Цей підхід не є best practice, однак він чудово підходить для ситуацій, коли потрібно швидко створити прототип і перевірити працездатність концепції на практиці.

Динамічна авторизація
У стандартному веб-застосунку авторизація відбувається між клієнтом та бекендом, де клієнт має статичні ідентифікатори. В MCP комунікація відбувається у форматі server-to-server, і найважливіша відмінність полягає у відсутності статичного client ID. Навіть при використанні звичних identity-провайдерів, таких як Google або Microsoft Active Directory, кожного разу при авторизації клієнт буде отримувати абсолютно інший ідентифікатор.
Замість цього використовується dynamic client registration — кожного разу при авторизації клієнт генерує новий, унікальний client ID, з яким і доводиться працювати бекенду для отримання доступу.

Кінець епохи ендпоінтів
При переході з класичного REST API на Model Context Protocol розробникам доводиться кардинально змінювати підхід до архітектури викликів. В MCP класичні ендпоінти залишаються лише як суто технічні абстракції, необхідні виключно для того, щоб клієнт міг встановити з'єднання. Вся реальна бізнес-логіка та взаємодія будуються навколо нової сутності — Tools.
У традиційному веб-застосунку логіка є жорстко детермінованою: користувач натискає конкретну кнопку на фронтенді, і система викликає чітко визначений API. В MCP усе працює інакше: мовна модель самостійно вирішує, що, як і коли викликати. ШІ обирає необхідний інструмент не за жорсткими правилами коду, а виключно на основі семантики: опису інструменту, його назви, параметрів та метаданих.
Помилка як частина контексту
При роботі з REST для обробки помилок достатньо повернути відповідний HTTP статус-код і короткий меседж. В MCP помилка стає повноцінною частиною контексту для ШІ. Згідно з найкращими практиками, якщо сервер вертає помилку, вона має бути максимально розлогою та зрозумілою, щоб модель знала, якими мають бути її наступні кроки для вирішення проблеми.
Втім, на етапі MVP команда не переписувала всю логіку обробки помилок, а продовжувала повертати звичайні REST-помилки. Виявилося, що сучасні LLM вже настільки потужні та розумні, що в більшості випадків їм достатньо статус-коду та мінімального опису, аби зрозуміти контекст і правильно відреагувати. Але при побудові надійного enterprise-рішення детальним повідомленням про помилки варто приділити окрему увагу.
Дизайн тулів
При міграції існуючого бекенду на MCP першим і найочевиднішим кроком здається автоматичний мапінг усіх REST-ендпоінтів у тули в пропорції один до одного. Це найпоширеніша помилка. Такий підхід не лише перевантажує контекст, але й заплутує мовну модель. Оскільки ШІ обирає інструменти виключно на основі їхніх описів, назв параметрів та метаданих, наявність десятків дрібних тулів призводить до того, що модель починає викликати некоректні інструменти в невідповідних ситуаціях.
Щоб уникнути цього, команда Avenga рекомендує змінити фокус: сприймати MCP-клієнта не просто як сервіс, що викликає інший сервіс, а як «людину», що виконує цілісне завдання. Користувачу зазвичай не потрібно просто отримати якусь ID — йому потрібно пройти певний флоу. Тому найкращою практикою є агрегація кількох ендпоінтів у один комплексний тул. Наприклад, в їхньому проєкті був створений інструмент bit selection recommend, який під капотом самостійно підтягує кілька додаткових сутностей і виконує одразу декілька викликів.
Головне правило дизайну: загальна кількість MCP-тулів має бути суттєво меншою за кількість реальних REST-ендпоінтів.
Відмова від Multi-tool викликів
Важливим архітектурним рішенням на етапі MVP стала свідома відмова від підходу мультивикликів (коли мовна модель викликає один інструмент, отримує проміжний результат, а потім сама вирішує викликати наступний інструмент у ланцюжку). Замість цього розробники сфокусувалися виключно на одиночних викликах. Навіть згаданий вище тул bit selection recommend працює саме так: він не покладається на те, що ШІ здогадається по черзі викликати різні сервіси. Навпаки, цей комплексний інструмент виступає єдиною точкою входу, а вже його внутрішня логіка самостійно знає, які мікросервіси потрібно викликати для формування фінальної відповіді. Це суттєво зменшує ймовірність того, що модель заплутається під час виконання складного завдання.
Також важливу роль відіграє семантика. Те, як ви називаєте тул, як описуєте його призначення та вхідні параметри, визначає успіх інтеграції. Разом з тим, варто оптимізувати об'єми даних: REST часто повертає дуже великі об'єкти з надмірною інформацією, тоді як для MCP їх потрібно робити максимально лаконічними, щоб економити токени та не переповнювати контекст моделі.
Окремим викликом є масштабування. Якщо у вас 5-10 тулів, можна використовувати статичний Tool Discovery — просто віддавати весь список інструментів клієнту одним пакетом під час ініціалізації. Проте, коли інструментів стає багато, цей підхід перестає працювати. У такому разі варто переходити до динамічного пошуку. Це можна реалізувати або через серверні нотифікації клієнту про зміну списку тулів, або через спеціальний патерн «tool search approach», коли створюється окремий інструмент для пошуку інших інструментів за текстовим запитом.
Виклики, оптимізація та інфраструктура
Створення MVP-версії MCP-сервера — це лише початок. Як тільки інструмент потрапляє до реальних користувачів, виникає низка інфраструктурних та архітектурних викликів, які вимагають оптимізації:
Docker partial build
Оскільки існуючий бекенд є великим монолітом, розробникам довелося переглянути підхід до створення контейнерів. Раніше вони формували дещо меншу версію API для деплою, але зараз перейшли до використання Docker partial build. Це означає, що збірка відбувається безпосередньо з окремих необхідних файлів, щоб у фінальному контейнері фізично не було того коду, який MCP взагалі не використовує. Це дозволяє суттєво зменшити розмір образу та прискорити деплой.
Версіонування та Observability
Наразі в MCP немає нативного підходу до версіонування тулів (як, наприклад, версіонування ендпоінтів у REST). Якщо потрібно змінити логіку інструмента, ви по суті маєте створити новий тул, а попередній позначити як deprecated у його описі, сподіваючись, що модель правильно зрозуміє ці вказівки та обере актуальну версію.
Крім того, критично важливим є моніторинг помилок. Команда активно впроваджує автоматизовані метрики та логування. Зокрема, розробники вдосконалюють збереження історичних дій користувача в базі даних (наприклад, коли інженери роблять специфічні обрахунки через Claude), щоб мати повний контекст взаємодії з ШІ.
Рейт-ліміти — це must-have
Після релізу MVP-версії для внутрішніх інженерів та науковців стало очевидно, що запровадження обмежень на кількість запитів є критичною необхідністю. Виявилося, що користувачі дуже активно взаємодіють із моделлю, а сам MCP-клієнт схильний постійно повторювати запити у разі невдачі чи недостатнього контексту. Це створило несподівано високе навантаження на бекенд навіть при відносно невеликій кількості тестувальників. Тому rate limits стають обов'язковим елементом стабільності MCP-сервера.
Отже, перехід від класичного REST API до Model Context Protocol — це не просто переписування коду, а фундаментальна зміна парадигми взаємодії між системами. Створення власного MCP-сервера дозволило вирішити головну бізнес-проблему: дати можливість інженерам використовувати LLM, спираючись на точні дані бекенду, повністю уникаючи ризиків галюцинацій ШІ при складних розрахунках.



