
Епоха Compute Crunch: куди зник безлімітний інференс і як економити токени
- Катерина Шевченко

- 26 трав.
- Читати 9 хв

Ще рік тому розробники та ШІ-ентузіасти сприймали compute як каву в офісі — гарантований невичерпний ресурс, на який не діють закони економіки. Оформи підписку за $20 на місяць і ганяй нейромережі «і в хвіст, і в гриву». Індустрія вірила, що контекстні вікна моделей скоро проковтнуть весь GitHub, а масштабування моделей триватиме вічно.
Настав 2026 рік. Користувачі масово вперлися в ліміти повідомлень, пакети в Cursor тепер тануть за кілька днів, а рахунки за API нагадують номери телефонів. Ласкаво просимо в епоху Compute Crunch. Виявилося, що алгоритми навчилися думати швидше, ніж людство здатне будувати дата-центри та генерувати для них електроенергію. Разом з Владиславом Прудіусом, Software Engineer у Genesis, заглянемо за лаштунки дефіциту обчислень, розберемо, куди зникають мільйони токенів, і дізнаємось, як їх економити без втрати якості відповідей.

Гігаватні рахунки за світло: чому compute став дефіцитом
Раніше ШІ-перегони виглядали просто: достатньо було нарощувати кількість чипів Nvidia та інженерних ресурсів — і на виході з'являлася потужніша модель. 2026 року ця схема зламалася. Новою «валютою» ШІ-економіки стали енергія, охолодження та дата-центри.
Попит на обчислення став настільки агресивним, що капітальні витрати окремих техногігантів давно пробили планку у $100 мільярдів на рік. За даними Goldman Sachs, лише у 2026 році світові витрати на ШІ-інфраструктуру становитимуть рекордні $765 мільярдів, а до 2031 року вони зростуть до $1,6 трильйона щорічно.
Проблема в тому, що ці гроші не конвертуються у прибуток так швидко, як очікували інвестори. Попри багатомільярдні доходи, OpenAI продовжує працювати в глибокий мінус: вартість інференсу й тренування нових моделей з'їдає виторг швидше, ніж він надходить. Фінансова директорка OpenAI Сара Фріар чесно визнає: через хронічний брак обчислювальних потужностей компанії доводиться йти на важкі компроміси й буквально відхиляти вигідні комерційні контракти, бо їх просто немає на чому крутити.
Цей дефіцит швидко доходить до кінцевого користувача. Користувачі ChatGPT і Claude масово вперлися в ліміти повідомлень, пакети в Cursor тануть за лічені дні, а підписники Claude Max за $100 на місяць здивовано виявляють, що інтенсивна сесія може зʼїсти весь місячний пакет за кілька годин. В Anthropic офіційно підтвердили, що динамічно коригують ліміти використання залежно від поточного завантаження серверів — тобто ваш «безлімітний» план насправді обмежений поточним станом GPU-кластера в іншій півкулі.
Кейс OpenClaw: справжня ціна автономної розробки
Найбільш показовим прикладом цієї проблеми стала історія від Пітера Штайнберґера, творця ШІ-агента OpenClaw. Команда з трьох людей запустила паралельно близько 100 інстансів Codex в автономному режимі для повного циклу розробки (від рев'ю пулл-реквестів і пошуку вразливостей у комітах до написання фіксів) і зафіксувала рекордні витрати. 15 травня 2026 року Штайнберґер опублікував у X скриншот дашборду CodexBar, який показав $1 305 088,81 витрат на OpenAI API за 30 днів — рахунок покрив 603 мільярди токенів і 7,6 мільйона запитів. Лише за день публікації скриншота акаунт зафіксував $19 985,84 витрат і 206 000 запитів. Рахунок повністю покриває OpenAI, де Штайнберґер працює з лютого 2026 року, а сам розробник описує це як дослідницький експеримент щодо того, як виглядала б розробка ПЗ, якби вартість токенів не була обмежувальним фактором.

Причина такої стрімкої перевитрати бюджету криється в логіці функціонування сучасних автономних агентів, які є надзвичайно марнотратними щодо обчислювальних ресурсів. Щоб виконати будь-яку дрібну дію, агент змушений щоразу відправляти в модель повний контекст: усю історію попередніх кроків, системні інструкції та поточний стан репозиторію. Коли сторонні автономні системи обходять оптимізацію промпт-кешування, цей обсяг даних розростається за експонентою. Модель змушена повторно зчитувати мільйони вхідних токенів на кожній ітерації, що робить повну автономію дуже витратною.
Анатомія токена: за що насправді платять
Цифри з кейсу OpenClaw виглядають як аномалія — рекорд одного ентузіаста, що має мало спільного з повсякденною роботою. Але той самий механізм, що згенерував рахунок на $1,3 мільйона за 30 днів, працює в будь-якій сесії з Cursor — просто з іншими множниками. Щоби це контролювати, варто розібратися, як саме провайдери рахують вартість запиту.
Що таке токени і як вони витрачаються
Щоразу, коли ви відправляєте запит до ChatGPT, Claude або Gemini, текст не передається моделі «як є». Спершу він проходить через токенізатор, який розбиває його на невеликі фрагменти — так звані токени, кожен з яких отримує числовий ідентифікатор. Саме з цими числами й працює модель.
Один токен — це приблизно 4 символи або ¾ англійського слова. Фраза «Hello, world!», наприклад, займає 4 токени. Але не весь текст токенізується однаково ефективно — саме ці нюанси впливають на якість відповідей і на вартість роботи.

Кожен провайдер використовує власний токенізатор:
OpenAI — tiktoken (алгоритм BPE)
Anthropic — власна BPE-модифікація
Google (Gemini/Gemma) — бібліотека SentencePiece (також BPE-подібний)
Головна відмінність між ними — обробка пробілів. BPE одразу розділяє текст по пробілах, тоді як SentencePiece трактує пробіл як звичайний символ. Це дає SentencePiece кращу якість для мов із нестандартним розбиттям на слова, але BPE залишається швидшим і стабільнішим для англомовних текстів. Отже, той самий текст може давати різну кількість токенів залежно від провайдера. Подивитися, як конкретна модель токенізує ваш текст, можна на OpenAI Tokenizer.
Контекстне вікно: заявлений максимум ≠ реальна ефективність
Контекстне вікно — це загальний обсяг токенів, який модель може «тримати в голові» під час однієї сесії: ваш промпт, історія діалогу, завантажені файли і сама відповідь. Актуальні ліміти провідних моделей:
Модель | Максимальний контекст |
Claude Opus 4.7 | 1M токенів (API / Claude Code) / 500K (chat) |
Claude Sonnet 4.6 | 1M токенів (API / Claude Code) / 500K (chat) |
GPT-5.5 | 1M токенів (API) / 400K (Codex) |
Gemini 3.1 Pro | 1M токенів (API, preview) |
Але є нюанс, який рідко згадують у маркетингу: більшість моделей мають максимальне ефективне контекстне вікно (MECW) — точку, до якої точність реально тримається. Це значення зазвичай суттєво нижче від заявленого максимуму. Коли контекст виходить за межі MECW, починається явище, яке дослідники назвали context rot — поступова деградація відповідей зі зростанням обсягу контексту. Модель «губиться» в надто великому масиві інформації, і точність падає навіть на тих задачах, де раніше вона справлялася впевнено. Тобто заливати в 1-мільйонне вікно цілий проєкт «бо влізе» — це не лише дорого, а й шкідливо для якості.
З чого складається вартість роботи з LLM
Більшість кінцевих ШІ-сервісів продають підписки з фіксованою ціною та лімітами на використання. Але якщо ви підключаєте модель напряму від провайдера (або користуєтесь Bring Your Own Model у сервісах, які це підтримують), вартість рахується за формулою:
Total cost = (input tokens × input price) + (output tokens × output price)
При цьому output-токени коштують у 3-10 разів дорожче за input. Наприклад, для Claude Opus 4.7 це $5 за мільйон input токенів і $25 за мільйон output токенів; для Sonnet 4.6 — $3 і $15 відповідно.

Також є кілька неочевидних факторів, які суттєво змінюють реальну ціну:
Thinking tokens. Reasoning-моделі (Claude Opus 4.7, GPT-5.5 та інші) генерують внутрішні «роздуми» перед фінальною відповіддю. Користувач їх не бачить, але тарифікуються вони як output. Детальніше цей механізм розглянемо нижче.
Prompt caching. Claude і GPT дозволяють кешувати вхідні токени промпту, зменшуючи їхню вартість до 90%. Це критично для агентів з великим системним промптом, що повторюється в кожному запиті. Саме нехтування цим механізмом — одна з головних причин, чому автономні агенти на кшталт OpenClaw генерують такі рахунки: кожен крок повторно зчитує мегабайти контексту, які можна було б закешувати.
Зміни в токенізаторі. Коли провайдер оновлює токенізатор разом з новою моделлю, це може непомітно збільшити вартість. Claude Opus 4.7 при виході отримала новий токенізатор: ціна за токен лишилась тією ж, але для частини кейсів фактична вартість input зросла до +35% через зміни у співвідношенні token-to-word.
Для розрахунку й порівняння вартості між провайдерами зручно користуватися LLM Price Calculator від Artificial Analysis.
Мова та мова програмування — теж мають значення
Кирилиця, ієрогліфи, арабська — усі ці системи письма токенізуються значно гірше, ніж латиниця. Причина проста: токенізатори навчались переважно на англомовних корпусах. До цього додається UTF-8 encoding: текст українською займає більше байтів, що напряму збільшує кількість токенів у 2,5-3 рази і вартість запиту відповідно. Порівняння моделей у токенізації саме української мови можна знайти в цьому дослідженні.
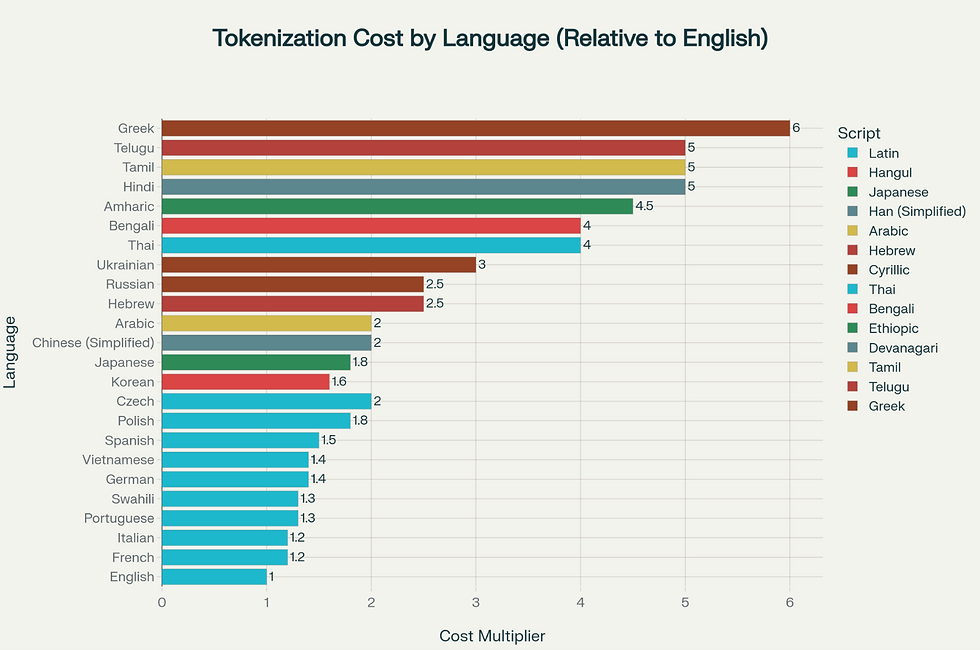
Те саме стосується і мов програмування. Динамічні мови в цілому більш token-efficient, бо не потребують явного зазначення типів. Наприклад, Python ефективніший за Go у цьому плані більш ніж у 1,5 рази. Детальне порівняння — на martinalderson.com.

Оптимізація: рівень щоденного використання
Управління контекстом: чому довгі чати — це погана ідея
Через context rot — деградацію якості зі зростанням контексту — найефективнішою звичкою є уникання довгих, multi-topic чатів. Ось базові принципи:
Один чат — одна задача. Не варто поєднувати в одному діалозі планування, реалізацію і дебагінг. Кожна нова задача або тема – новий чат.
Розділяйте сесії за типом. Окремий чат для загального аналізу й планування, окремі – для конкретних підзадач із вузьким контекстом. Це не лише покращує якість відповідей, а й дозволяє більш точно контролювати, яка інформація потрапляє до моделі.
Використовуйте вбудовані інструменти для менеджменту контексту. У Claude — це Projects з окремим контекстом і кнопка «New chat». У Cursor і Claude Code — команди /clear або /compact для стиснення або скидання контексту. Загалом, багато корисних рекомендацій щодо ефективного context engineering для AI-агентів можна почитати у Anthropic.
Передача контексту: чому Markdown — найдешевший формат
Коли потрібно передати LLM великий обсяг зовнішнього контексту (вміст сайту, документацію, статтю), формат файлу має пряме значення для токенів і якості обробки.
Markdown є найефективнішим форматом: до 87% менше токенів порівняно з HTML і до 70% економії порівняно з PDF. Причина проста: Markdown позбавлений важкої структурної розмітки, метатегів та візуального сміття, які не несуть семантичного навантаження для моделі, але справно тарифікуються провайдерами API.
Для конвертації використовують такі рішення:
Сайти → Markdown: Jina AI Reader — достатньо додати r.jina.ai/ перед будь-яким URL (наприклад, https://r.jina.ai/https://journal.gen.tech/news), і сторінка повертається у чистому Markdown.
PDF → Markdown: Any-to-Markdown — безкоштовний тариф дає до 50 конвертацій на місяць.
Caveman та міф про 75% економії на output-токенах
Торік на GitHub набрав понад 60,000 зірок репозиторій з так званим Caveman skill для Claude Code. Ідея проста: системний промпт змушує модель відповідати примітивно – лише іменники й дієслова, без граматичних зв'язок, коротко й «телеграфно». Заявлена економія: до 75% output-токенів.

Деякі бенчмарки показували лише 14-21% реальної економії від такого формату відповіді на практичних задачах. Також на практиці є декілька нюансів:
Output-токени у типовій Claude Code сесії становлять лише 5-15% від загального контексту. Основна витрата — це input: кеш репозиторію, файли, історія сесії. Навіть якби Caveman справді давав 75% економії на output, реальна загальна економія склала б 3-10% від усієї вартості інтеракції.
Так звані filler-токени («Certainly!», «I'd be happy to...») не є просто повністю зайвими словами. Для моделі вони виконують роль своєрідного обчислювального заповнювача — поки генерується малозначущий токен, модель формує наступний суттєвий крок відповіді. Крім того, примусовий стилістичний формат відповіді займає частину уваги (attention) моделі, яка тепер витрачається не лише на вирішення задачі, а й на дотримання стилю. Однак, наразі немає надійних публічних бенчмарків, які б дали точну відповідь, наскільки це впливає на якість роботи моделі.
Що гарантовано економить output-токени — це точність і конкретність у описі бажаного результату. І цього можна досягти без Caveman промпту на 552 токени. Кілька простих конструкцій, додані до системного промпту або безпосередньо до запиту, дають у реальних тестах схожий результат (до ~21% економії output токенів):
No filler, no preamble. Answer first.
Tool call first, explanation after.
Drop pleasantries. No hedging. Fragments fine.
Short synonyms. Pattern: [thing] [action] [reason]. [next step].Pro-поради
Серіалізація даних: CSV, JSON і чому варто знати про TOON
Коли потрібно передати структуровані дані в LLM — результати запиту з бази, конфіг, аналітику — більшість за замовчуванням використовує JSON. Це розумний вибір для складних даних із вкладеними об'єктами та масивами, але не завжди оптимальний з точки зору токенів.
Коротке правило:
Flat tabular дані (рядки й стовпці без вкладеності) — CSV буде найефективнішим: мінімум синтаксичного шуму, лінійна структура.
Складні дані з вкладеністю та зв'язками — тут зазвичай беруть JSON. Але є альтернатива.
У 2025 році з'явився формат TOON (Table-Oriented Object Notation), розроблений саме для передачі даних у LLM. Ключова ідея: замість того, щоб повторювати назви полів для кожного об'єкта, TOON зберігає їх один раз у заголовку, а самі значення розміщує в табличному вигляді з відступами — без дужок і зайвих лапок.

Офіційні бенчмарки показують економію 30-60% токенів порівняно з JSON (в деяких тестах — до 70–75%). Для передачі великих масивів однотипних об'єктів у LLM це наразі найбільш ефективне рішення.
Корисні посилання:
якісне порівняння форматів TOON, JSON, CSV, YAML
онлайн-конвертер JSON → TOON.
Thinking-моделі: коли вони виправдані і чому коштують дорожче
Частина сучасних LLM перед тим, як видати фінальну відповідь генерує внутрішні «роздуми» – так звані thinking tokens або reasoning tokens. Ці токени не відображаються у відповіді, яку бачить користувач, але тарифікуються як output.
Що це дає: модель має можливість явно дослідити кілька підходів, перевірити проміжні результати й лише потім зафіксувати відповідь. Для складних задач із багатокроковою логікою це суттєво покращує якість — модель значно рідше «ковзає» по поверхні проблеми.
Аналіз 45+ reasoning-моделей показує, що в середньому thinking-модель генерує майже у 6,5 разів більше токенів, ніж відображає у фінальній відповіді. Тобто видима відповідь у 200 токенів може насправді споживати 1,500 і більше токенів.
Для прикладу, thinking mode підтримують Claude Opus 4.7, Claude Sonnet 4.6, GPT-5.5, Kimi k2.5 тощо; без thinking mode — Claude Sonnet 4.5, Gemini 3.1 Flash та попередні покоління більшості моделей.
Adaptive thinking — це офіційно рекомендований режим для frontier Claude моделей. У цьому режимі модель сама оцінює складність запиту і вирішує, чи думати перед відповіддю. На ймовірність увімкнення thinking впливає також параметр effort, виставлений для запиту. Для AI-агентів adaptive thinking особливо корисний, оскільки дозволяє моделі продовжувати думати між послідовними викликами інструментів (tool calls).
Thinking Mode дійсно виправданий в таких кейсах:
Планування для агентів — задачі, де потрібно декомпозувати мету на кроки і вибудувати правильну послідовність дій.
Синтез складних документів — cross-referencing між кількома джерелами, виявлення суперечностей, підготовка аналітики.
Multi-step завдання зі складними вимогами — будь-яка ситуація, де рішення має відповідати кільком обмеженням одночасно і де помилка на проміжному кроці тягне за собою каскад помилок далі.
Для рутинних запитів, прямих питань і простих трансформацій тексту увімкнений thinking mode буде просто зайвою витратою як токенів, так і часу на очікування відповіді, оскільки якість відповіді не буде помітно вищою.
Отже, Compute Crunch — це новий базовий стан індустрії, який триватиме, доки попит на інференс випереджатиме темпи побудови дата-центрів. Ефективність промптингу стає окремою інженерною дисципліною. Раніше «вміти користуватися ШІ» означало просто формулювати запит. Тепер це означає розуміти, як рахується токен, коли модель повторно зчитує контекст, і де reasoning-режим подвоює рахунок.



